Durch einen Klick auf den Button „TTS-Ansage“ öffnet sich ein neues Fenster, in welchem Ansagen durch die Eingabe von Text computergeneriert erstellt werden können. Der TTS-Generator hat drei Einstellungsmöglichkeiten: Sprache, Sprecher und Eingabemodus.
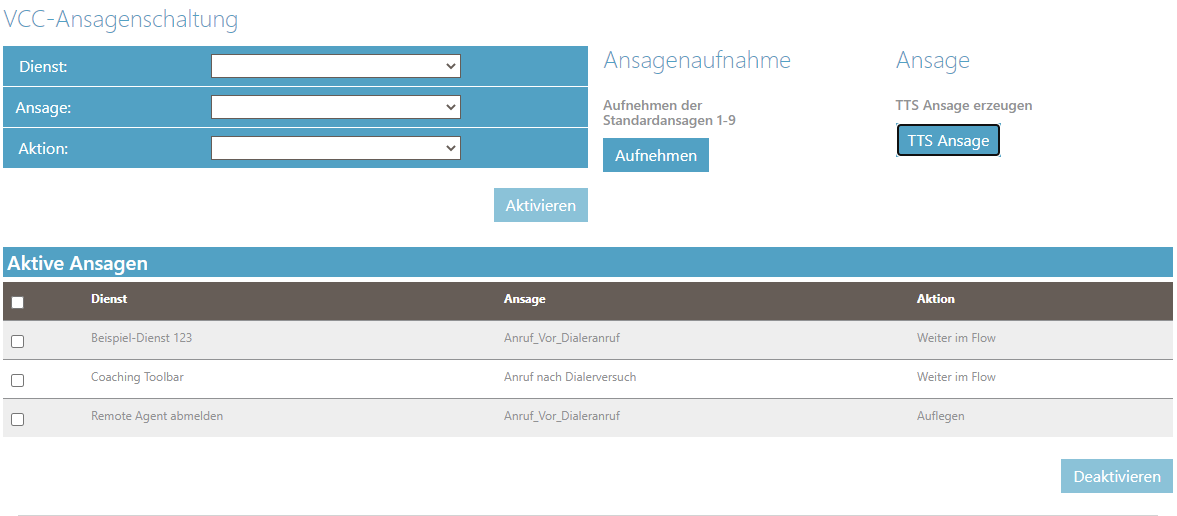
Die erste Einstellung, welche getroffen werden kann, ist die Sprache, diese stellt die Sprache der verschiedenen Sprecher ein, diese sollte immer mit der Sprache des eingegebenen Textes übereinstimmen. Die nächste Einstellungsmöglichkeit ist die, des Sprechers, die Auswahl der verschiedenen Stimmen erfolgt über das Dropdown-Menü.
Sind diese Einstellungen getroffen, kann in das Textfeld „Text“, die zu sprechende Ansage eingegeben werden und durch den Button „Abspielen“ getestet werden. Sind sie mit dem Ergebnis zufrieden, so kann in dem Textfeld, mit der Beschriftung „Name“, der Dateiname angegeben werden und mit einem Klick auf Speichern gespeichert werden.
Sobald die Ansage erstellt und gespeichert wurde, kann diese wie gewohnt über den Menüpunkt “VCC-Ansagenschaltung” verwendet werden.
SSML Modus
Durch das Auswählen SSML in der unteren linken Ecke kann mithilfe von dieser Sprache die Ausgabe von Text, durch verschiedene Emotionen, oder auch verschiedene Sprecher noch realistischer dargestellt werden.
Ein Beispiel:
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="en-US">
<voice name="en-US-JennyNeural">
<mstts:express-as style="cheerful" styledegree="2">
That'd be just amazing!
</mstts:express-as>
<mstts:express-as style="advertisement_upbeat" styledegree="0.01">
What's next?
</mstts:express-as>
</voice>
</speak>